SampleVAE - A Multi-Purpose AI Tool for Music Producers and Sound Designers
Revealing some of the tools of the MUTEK AI Music Lab

Photo of one of our other AI music projects - AI DJ.
A little bit over one year ago I completed a project I called NeuralFunk. The basic idea behind it was to produce a full Drum & Bass track using only samples that were generated by neural networks.
See this article here for more details.
The finished track and my detailed write-up of how it was done (see link above) gained a fair bit of attention and was accepted to the Workshop on Machine Learning for Creativity and Design at NeurIPS 2018. For me, it lead to a lot of interesting opportunities. In a very convoluted way, it is even the reason that I’m now writing a book on the importance of Time Off.
However, despite the success of the project and the many ideas I had for further developing it, I just let it sit for a very long time.
But then a few months ago, MUTEK Japan approached Qosmo, the company I’m working for, with the idea of an AI Music Lab, and asked us if we would be interested in being the technical R&D partner for the Lab. And we agreed.
MUTEK is one of the world’s leading festivals for electronic music and digital art. Originally from Montreal, MUTEK is now held annually in several cities around the world, with Tokyo being one of them.
The AI Music Lab, held from November 9 to 19, will bring together 15 artists from around the world to explore the applications of artificial intelligence to music production and performance.
Citing from the MUTEK.JP website,
Participants of MUTEK.JP AI Music Lab will study three genres — soundscapes, noise and techno — comparing traditions, modern state and the future of three genres within the specific context of the Japanese cultural background. The main task of the laboratory is to create new works using AI / ML technologies with the participation of experts in the field of machine learning and artificial intelligence.
A selection of some of the best results will then be performed at the main MUTEK.JP festival in December.
Once we had agreed to act as technical partner for the Lab, I decided it was the perfect occasion to revive the tools I had used for NeuralFunk, further develop them, and also package them in a more user-friendly way so that music producers without too much coding or machine learning background could use the.
The result of this effort is a tool I call SampleVAE.
All the code is available online.
You can use it as a pre-trained black-box tool (see the Readme and Jupyter notebook with examples), train on your own datasets, or dive into the code and completely make it your own. It comes with three simple pre-trained models, but can also easily be trained on custom datasets.
The tool has three main functions:
Generate sounds in several unique ways
Classify sounds into distinct classes
Find similar sounds in a large sample library
I will go into each of these functions below. But let’s briefly talk about the technical aspects.
I call it SampleVAE because it is essentially a Variational Autoencoder (VAE) that works on audio samples as its input and output data.
Slightly more detailed, it’s a convolutional VAE with Inverse Autoregressive Flows and an optional classifier network on top of the VAE encoder’s hidden state. The audio is processed in terms of Mel Spectrograms. The model is implemented in TensorFlow.
For some more details on the audio processing and the model, have a look at my article on NeuralFunk (or the SampleVAE code itself, of course). If you’d like to learn more about Variational Autoencoders, I wrote an easy to understand three part series explaining them from a somewhat unique but hopefully insightful angle, in terms of a two-player game.
While there are several existing AI tools for music producers out there, and many of them are really good for specific users and purposes, most of them are either too difficult for the average musician without deep learning background to use, or they are too limited in what they allow the user to do.
I hope that SampleVAE is both highly customizable and able to fit many different use cases, but at the same time easy enough to set up and use with only limited programming experience.
Initialising the tool from a trained model is as simple as running the following code in a python session.
from tool_class import *tool = SoundSampleTool(model_name, library_directory)It is also light enough to be trained on reasonably large datasets without a GPU, and fast enough during inference to be potentially integrated into live performances using a standard laptop.
The tool itself is still at an early stage, and I’m excited to see how actual artists, in the MUTEK AI Lab but also elsewhere, are going to use it. It is so flexible that the use-cases are almost endless, and I’m excited to see what ideas people come up with. I hope that I can use these ideas to further develop the tool, or that other people will take the code and adjust it for their very own purposes.
With all that being said, let’s have a brief look at the tool’s current functions.
Generating Sounds
VAEs are generative models. This means that after being trained on real data, they can generate seemingly realistic data by taking points from their latent space, and running them through the decoder.
SampleVAE makes use of this to provide several unique ways to generate audio (or rather spectrograms, which are then converted to audio via the Griffin-Lim algorithm).
Random Sampling
The simplest way to generate a sound (and save it to a file called 'generated.wav') is to just pick a random point from latent space and run it through the decoder.
tool.generate(out_file='generated.wav')The results are literally very random. They tend to fall within the category of sounds the model was trained on, e.g. drum sounds, but often also produce very unique and alien-sounding sounds.
Re-Generating a Sound
Another way is to take an input file, find its embedding, and then decode this again. This can be seen as a kind of distortion of a sound.
tool.generate(out_file='generated.wav', audio_files=[input_file])This gets even more interesting when using the additional variance parameter to add some noise to the embedding before decoding. This can generate infinite variations on the same input file.
Combining Multiple Sounds
Maybe the most interesting way to generate new sounds is to combine multiple sounds.
tool.generate(out_file='generated.wav', audio_files=[input_file1, input_file2])This embeds all files passed in, averages their embedding, and decodes the result.
Optionally, one can pass the weights parameter, a list of floats, to combine the vectors in ways that are not simple averages. This allows for example to add more of one sound and less of another (and also to interpolate between sounds).
In addition, it allows for other interesting embedding vector arithmetic, such as subtracting one sound from another. For example subtracting a short sound with high attack from another sound might soften that sound’s attack.
Of course all this can be combined with the variance parameter to add randomness.
Sound Similarity Search
Most producers will know this issue. You have a sample that sort of works, but you’d like to experiment with other similar samples. The problem is if you have a large sample library, it gets extremely hard to find samples. So you often end up using the same ones over and over again, or settle for something that’s not ideal.
The find_similar function of the SampleVAE tool allows you to solve this issue, by looking through your sample library (specified when initialising the tool), comparing embeddings, and returning the most similar samples.
For example, if I want to find the five most similar sounds to a particular snare sample, I can run the following code to get a list of the files, their onset times (more on this in a second), and their Euclidean distance from the target file in embedding space.

Finding similar files to a given snare sound.
The library used in the above example was small, only a few hundred drum sounds. But the tool found several similar snare sounds, as well as some hihat sounds that apparently sound very snare-like. Note that the file it deemed most similar (with distance zero) was actually the input file itself, which also happened to be contained in the library.
The current implementation of SampleVAE treats all samples as exactly two seconds long. Longer files get cropped, shorter ones padded. However, for the sake of the sample library, one can specify library_segmentation=True when initialising the tool to segment larger files into multiple two second slices. The onset (in seconds) then marks where in the long file the similiar sample is.
This could for example be useful if you have long field recordings and would like to find particular sounds within them (as might be applicable in the soundscapes genre of the Lab).
Classification
Finally, the tool can be used to classify samples into several unique classes. Two of the pre-trained models have a classifier associated with them.
The first one, model_drum_classes, was trained on a dataset of roughly 10k drum sounds, with a classifier of nine different drum classes (e.g. kick, snare, etc). The confusion matrix for this model is below.
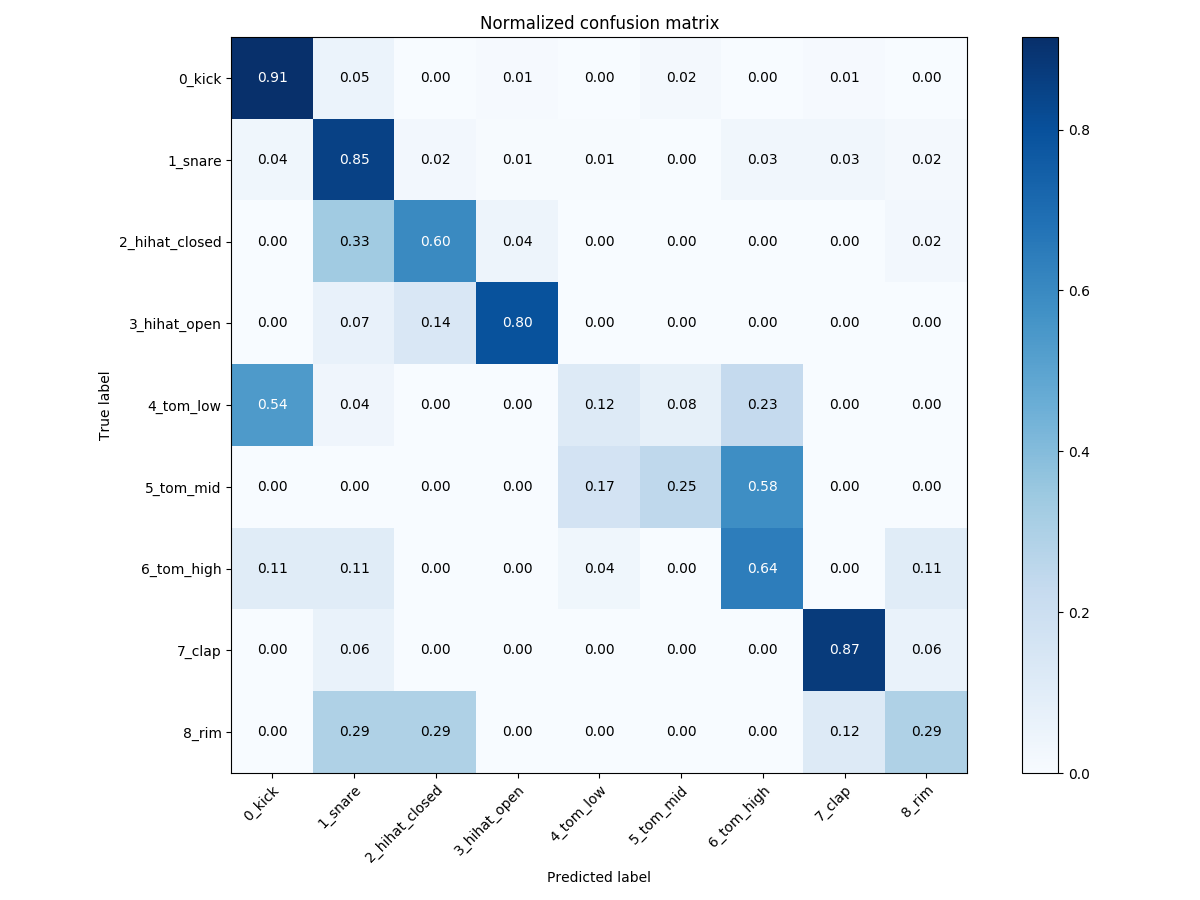
Confusion matrix for a model trained to predict nine drum types.
We can see that many classes are recognised fairly well, with a fair amount of confusion between the low, mid, and high toms.
To use the prediction function, simply run
probabilities, most_likely_class = tool.predict(input_file)This return a probability vector over all classes, as well as the name of the class with the highest probability.
The potential applications of this kind of classification are large. For example, our interactive audiovisual installation Neural Beatbox, which was exhibited at the Barbican Centre in London this summer, uses this kind of classification as one of its main AI components.
The second pre-trained model, model_drum_machines, was trained on a small dataset of roughly 4k drum sounds, with a classifier of 71 different drum machines (e.g. Akai XR10, Roland TR-808, etc). Again, the confusion matrix for this model is below.

Confusion matrix for a model trained to classify sounds into 71 drum machines (e.g. Roland TR-808). This is not meant to show a good result, the dataset was tiny, with only a handful of examples per class. It is merely meant to show what’s possible.
The dataset is way too small for such a complex classification task, but I included this model simply to show another idea of what is possible.
These are the main functions of the current tool. You can use them with the pre-trained models straight away.
But what if you want to train on your own data? Also very easy!
Training Your Own Model
Preparing a Dataset
Before you can train a model, you first need to generate a dataset of samples. Luckily, there is a simple script to do this:
python make_dataset.py --data_dir root_dir --dataset_name my_datasetThe above call finds all audio files in root_dir (and nested directories), splits them randomly into train and validation data (with a ratio of 0.9 by default), and saves them as a dataset called my_dataset.
If you want to prepare a dataset with classifier information, simply run make_dataset_classifier.py instead. This will treat the immediate sub-directories of root_dir as unique class names, and then look for all audio files inside them.
Training a Model
Now that you have a dataset prepared, you can train your model. Again, it’s as simple as
python train.py --logdir model_name --dataset my_datasetThe script will automatically lower the learning rate and check for convergence and stop the training when it thinks the model is fully trained (but you can also override all this if you want more control).
And that’s it. Now you’ve got your own model that you can use with the tool.
Improvements, Issues, and Ideas
As mentioned above, this tool is at a very early phase, and there is lots of room for improvement. Here I want to mention a few ideas that I might want to explore at some point, or that maybe someone else is willing to tackle.
One issue is that the tool can currently only handle durations of exactly two seconds. The reason for this is mainly in the de-convolutional decoder, which currently has its shapes hard-coded to the spectrogram shapes of two second audio.
Related to this, while the whole feature processing pipeline actually supports much more advanced and customizable features than just Mel Spectrograms, changing the options also changes the shape of the tensors, which again makes the current decoder crash.
Automatically determining the shapes of the decoder given the audio parameters would solve both these issues.
Another problem with the current decoder is that it produces spectrograms that are low in detail and quite blurry (a common issue with convolutional VAEs), which leads to lower definition audio samples. Trying different decoder approaches might lead to better quality of the generated audio. If you dive into the code, you’ll actually find an option to enable a weird RNN combination stacked on top of the de-convolutional network. I was briefly experimenting with this but didn’t go too deep into it after some strange early results.
Trying a completely different encoder/decoder architecture which can operate directly on audio (e.g. WaveNets) might also be promising. The reconstruction of audio from spectrograms always comes with losses/noise, so bypassing this step entirely might lead to even higher quality sample generation.
For models with classifiers, there is no guarantee that the classifier part and the VAE part converge at the same rate. And while for the VAE a bit of overfitting actually seems desirable to get sharper spectrograms, the classifier should not overfit (well, someone might come up with a creative use for an overfitted classifier too). It might be nice to have different learning rates for the main and classifier networks. Or an option to freeze the weights of the encoder and classifier, and only keep training the decoder.
Support for semi-supervised classifiers would be nice too in cases where only a few class examples are known in a large dataset. The model code actually contains parts from an older semi-supervised model I used (sorry, my code tends to be a bit messy…), which could be revived fairly easily, and the dataset generation could also be adapted to this case without too much trouble.
Currently some of the generated samples contain noise. Especially short sounds that decay quickly have a long “noise tail”. However, this noise seems very characteristic for the samples generated with this tool. Hence, it might be reasonably straight forward to add a noise removal operation to the sound generation step.
The optional segmentation of the sample library currently seems to be a bit too sensitive. It occasionally splits long sounds with a slow decay, like cymbals, into multiple sounds.
As you can see, lots of things to improve, and I’d be happy to see other people contributing to this too.
But above all, I’d love to see what use cases people can come up with. As mentioned before, the tool itself is lightweight and fast enough to integrate it directly into the production workflow or even live performances. Wrapping it into e.g. a Max for Live device could be cool. With a two-dimensional latent space, it could even generate sounds directly from points on a 2D grid controlled by a pad.
The possibilities are endless.
Other Tools
SampleVAE is not the only tool Qosmo is bringing to the MUTEK AI Music Lab. While I was working on SampleVAE, Nao Tokui was working on a rhythm generation tool.
He even did integrate the tool directly into Ableton Live, one of the main digital audio workstations, as a Max for Live device. The tool can be directly trained and run within Live.
Currently, Nao is working on a similar tool for melody generation.
And besides Qosmo’s custom made tools, we will be exploring many other publicly available AI music tools during the lab.
If you happen to read this in time, and also happen to be in Tokyo on Sunday the 17th November, come join us for a public event at EDGEof in Shibuya. Several of the team members and facilitators will give talks, including one by me about some of the technical aspects, and some of the early project ideas will be previewed.
Otherwise, stay tuned for the main performances at the MUTEK.JP festival from December 11 to 15.
And get creative with SampleVAE!