NeuralFunk - Combining Deep Learning with Sound Design
Making a Track Entirely out of Samples Generated by Neural Networks

[UPDATE December 2019: I recently packaged some of the code I used for sample generation into a much more easy to use tool called SampleVAE. You can find it here.]
For a long time now I have wanted to combine my passion for music with my work in artificial intelligence. But I kept putting it off. I felt that I needed to improve my music production skills first before trying to get deep learning involved in the process.
But then in mid September I saw that there was going to be another workshop on Machine Learning for Creativity and Design at this year’s Neural Information Processing Systems (NIPS) conference, arguably the biggest event for the AI community every year. And the submission deadline for artworks and music was the end of October.
That, as well as a chat with Nao Tokui over quite a few beers around the same time, inspired me to finally get off my ass, stop using excuses, and start working on something. I had about a month to get something done in time for the workshop deadline.
The result is NeuralFunk, an entirely sample based track, in which all the samples were generated by deep neural networks.
It didn’t exactly turn into a typical Neurofunk track as I had originally intended but instead developed into something quite unique. It’s dark, chaotic and exhausting, almost suffocating the listener, leaving no time to rest and take a breath. NeuralFunk is as experimental as the way in which it was produced.
[Update: NeuralFunk, as well as another artwork of mine got accepted to the NIPS workshop, and you can also listen to it as well as my other tracks on Spotify now.]
In the following I want to tell you how this project came about, both from a deep learning as well as a music production perspective.
If you’re only interested in one of these aspects, feel free to skip the other parts. I’ll also share links to some of the code and the generated samples.
But before going into any of the details, I want to give some huge thanks to the people who contributed to this. Alvaro for designing the cover image, Makoto for sharing his sample library with me, Nao for inspiring me on several occasions to get this project started, and finally above all D.A.V.E. for collaborating with me on the track itself (but more on that later). Thanks guys, you’re awesome!
The Origins of NeuralFunk
My initial entry into electronic music production came through finger drumming, and this is still how I would mainly define myself as a producer. So my first ideas for combining deep learning and music were actually quite different.
I wasn’t planning to make a full track, or even generate any audio. Instead I was thinking of interesting ideas for live performances. Specifically, I was thinking of a system that could determine similarities between audio samples so that I could automatically swap out sounds for other similar sounds.
As a simple example: I might have a particular snare sound, but I would like to replace it with a similar but slightly different sound.
In a more experimental setting I might want to record my audience or random soundscapes at a venue, and then automatically extract sounds from that to replace the actual samples I was using. That way I could gradually morph from a track that was based fully on well produced and manually picked samples to something much more organic and random, possibly even with audience interaction, that could still kind of keep it’s original sonic character.
Besides being a cool performance tool, a good way for finding similar samples could also help a lot during production. Pretty much every producer knows what a painful and time consuming process it can be to find exactly the right samples in an ever growing library, often spread over many random directories and nested sub-directories.
When I talked about this idea to Makoto well over a year ago, he was kind enough to give me his massive sample library to play around with. At that time however I didn’t take it very far. After messing around with it a little bit, I got back to my old excuses of first focusing on music production itself.
But now I had a good reason to finally get something done quick: the NIPS workshop deadline.
However, I concluded that my original idea wouldn’t be realisable given that I had only a month for this project. The deep learning part wouldn’t be an issue, but developing the backend for the live performance and working out an interesting routine would take more time, especially since I don’t have much experience yet in Max for Live (or any other development environment that could work for this).
Instead I decided to produce a track.
My main genre is Drum & Bass. And the subgenre of Neurofunk, given its name which was also the inspiration for the track title, just seemed like a perfect match.
Neurofunk is a generally dark and aggressive subgenre of Drum & Bass. Among other things, it’s characterised by very elaborate and complex sound design, especially the basslines. For a great recent example of this, check out the bass starting at around 0:44 in “LSD” by Document One. For a bit more “traditional” Neurofunk, check out “Pulsation” by InsideInfo and Mefjus.
This complex sound design also seemed to match my intention of using neural networks for the purpose. However, most Neurofunk producers heavily rely on sophisticated wavetable or FM synthesis to carefully shape their sounds. Going fully sample based might be challenging. Besides, Neurofunk tends to be very precise and sharp. Both attributes I wasn’t sure the neural net approach would give me in my sounds.
Still, I was up for the challenge. Moreover, the samples were only the starting point.
While I set myself the restriction that every sound had to originate from a sample generated by a neural net, I didn’t set any limits on what effects or post-processing I could use on them, leaving me lots of freedom to shape the sounds.
In this way I think NeuralFunk differs from most other approaches to AI assisted music generation.
In many cases people either, like in Performance RNN, let the AI model note sequences through MIDI generation, or use deep learning for synthesis of particular instruments, like NSynth.
Synthesising all the sounds via deep learning and then producing a track from it is not something I have come across so far, although I’d be very surprised if I was the first one to do this. Although this might be the first Drum & Bass track created this way.
The result is clearly not music made by AI. But it’s music made using AI as a tool for sound design and for exploring new ways of creative expression.
The Deep Learning Phase
Given the very rough idea, the next step was to figure out what kind of network to use to actually generate the samples.
Not quite sure yet what direction I wanted to take this in, I again got some inspiration from Nao. He has an iPython Notebook for sound classification from spectrograms. I wasn’t interested in sound classification, but I figured some of the pre-processing could be useful, so I started playing around with it a bit, converting some of the samples in my library to spectrograms.
That’s when project NeuralFunk really started, with this spectrogram of an Amen Break on September 21.

After that I decided that a good (and kind of obvious) place to start with the actual neural networks would be to take a basic WaveNet, train it over my sample library, and see what comes out.
I started by collecting all the samples from my different sample directories. That was mainly Makoto’s samples, as well as my Maschine 2 Library, and the expansions Resonant Blaze, Prospect Haze, and Decoded Forms (all highly recommended by the way). I’m really grateful to Native Instruments for the fact that they make their samples directly available as wav files, not buried deep in the software.
I then converted all of them to 16kHz and trimmed anything longer than 10 seconds. There were some longer loops and entire tracks and stems, but I decided to ignore those, except for their beginning.
In the end I had about 62,000 samples (although I noticed much later that I could have had quite a bit more since my automatic search only looked for exact matches to “.wav” and “.aiff”, which missed a lot of variations like “.WAV”, “.aif”, etc).
Next I took this TensorFlow implementation of Wavenet and simply trained it on that data. I wasn’t expecting amazing results given the huge variation in the data, but it was a start, and worth trying. And I did actually end up getting some interesting results out of it. Although it was mostly, as expected, just (not quite random) noise.
To give the Wavenet a better chance to understand what data it was supposed to generate, I decided to add a conditioning network.
In addition to the audio files themselves, I also created and saved a spectrogram representation for the first three seconds of each file. My initial plan was then to add a complete convolutional encoder network that would be trained end to end with the Wavenet, taking the spectrogram as an additional input and compressing it to a conditioning vector.
Unfortunately, at least in my quick experiments, this proved too hard of a task and the Wavenet simply learned to ignore the conditioning vector before the spectrogram encoder could learn anything useful. This seems to be one of the many cases where a too powerful decoder prevents an encoder from learning. Maybe with some better parameter tweaking this process could work. But I didn’t have time for an extensive parameter search.
However, at the same time as playing around with the Wavenet, I still hadn’t given up on my initial idea of finding similarities between samples. My thinking was that I could use the Wavenet to just generate a huge amount of random samples, and then use the similarity search to find sounds that were close to particular reference sounds I liked.
So to get the similarity search working, I also wrote a Variational Autoencoder (VAE) that was trained on the same spectrograms. I could use the resulting embeddings to do similarity search simply by comparing distances in latent space.
But this model actually allowed me to do much more.
Instead of training an encoder end to end with the Wavenet, I could use the VAE’s embeddings as conditioning vectors for the Wavenet, which lead to much better results. The Wavenet now clearly made use of the conditioning information, and its output had many of the characteristics of the sound it was conditioned on.
But even beyond that, I could use the VAE’s decoder itself to reconstruct spectrograms and then use a Griffin-Lim algorithm to map back to audio.
Anyone who’s followed my writing on AI a bit or seen one of my talks knows that I really like VAEs. They’re probably my favorite class of model. Not only are they conceptually beautiful and very elegant from an information theoretical perspective, they are also extremely versatile.
Here a single model allowed me to create embeddings that I can use to condition another model, enabled me to do advanced semantic search, as well as actually generate novel sounds by itself.
It was also very easy to train, taking just a couple of hours on my iMac’s CPU to converge. The model itself was pretty simple too. It was actually the first time I wrote a deconvolutional network from scratch so I kind of quickly hacked it together, but it seemed to work.
Given the short time I didn’t really care about optimisation. As soon as something sort of worked, I moved on. None of what I did was rigorous in any way. I didn’t even bother splitting my data into separate test or validation sets.
The only slightly fancy thing I added to the VAE were some normalizing flow layers. Again, my experiments were far from rigorous, but adding a few flow layers seemed to qualitatively lead to better results overall.
I did the embeddings in 64 dimensions (no reason, just picked that number as my first test, it kind of worked, and I never bothered trying anything else). But using TSNE I could reduce the dimension to two for visualisation.
The original samples don’t have any category labels, so I used the filenames to extract a few approximate labels, looking for words like “kick” and “sfx” in the name. The results were surprisingly good. Here a visualistion of all the samples that fell within one of the eight classes I chose.
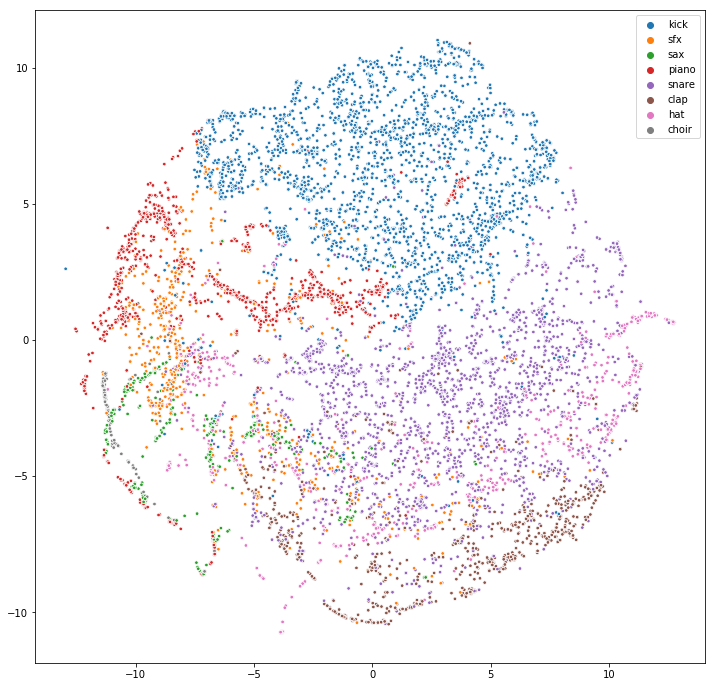
I was actually quite surprised how nice the clusters turned out, and also which clusters are adjacent to which (like the clap, hat, snare transition).
I did another visualisation including all samples (i.e. also the ones that didn’t have a matching label in the filename).

The results are not as nice, but that’s probably partially because I didn’t have the time or patience to fiddle with the TSNE parameters and just took the very first result I got ;)
Looking a bit more into the details of this, or even doing the embedding directly in two dimensions, could give some interesting insights, but I’ll save that for some other time.
All the code for the VAE, as well as some of the preprocessing and other random bits can be found here.
But be warned if you’re curious about the code. This was not really meant to be shared. It’s very hacky, badly (if at all) commented, and a lot of things are hardcoded to my audio processing parameters and directory structure. I might get around to polishing this off at some point, but for now be aware that it’s pretty messy.
I didn’t bother sharing my Wavenet code since all the more complicated things I tried didn’t actually work, and the thing that did work is really just a minor modification of the original implementation which allows to directly read and feed in pre-computed embedding vectors from “.npy” files and use them for conditioning.
The Sample Generation Phase
Having all the models in place, I could start to actually generate some sounds.
First was the VAE and Griffin-Lim combination. Essentially it gave me three ways to generate sounds.
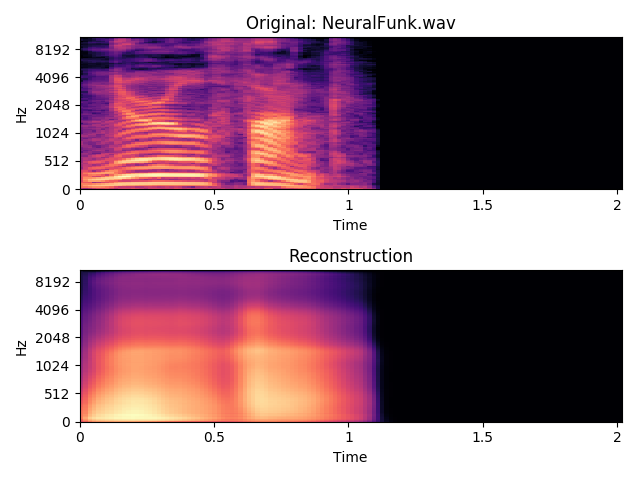
The simplest one was to just encode a spectrogram, decode it again, and then reconstruct the audio. An example would be this clavinet sample. We can see that the fundamental frequency gets preserved pretty well, but a lot of the other details get changed.

This beep is another good example. Again, the fundamental frequency and the overall outline is preserved, but at lot of the finer details are altered or lost.

The second way was to actually combine two or more embeddings, and then decode the resulting latent code. A nice example that actually ended up forming one of the main melodic elements was this combination of a kick drum and a vocal note.

The result is quite a nice harmonic sound, but the kick adds some interesting subby attack at the beginning, giving a nice stabby synth sound.
Here another example, combining three different inputs.

The generated sample is a kick sound, just like one of the inputs, but with lots of interesting character from the hi-hat and tabla.
Finally, I could also go without any input and simply sample directly from latent space. This lead to a lot of interesting results.
Some of them were clearly recognisable sound types, while others were much more random and experimental, but still useful as sound effects.

I’d like to say that at this point I followed a very clear and deliberate process of generating and designing sounds. But given the limited time, what I actually did was write a script that picked a random number between 0 and 3, then randomly chose that many input samples from my library, embedded them (or sampled an embedding from latent space if the number of input samples was zero), combined them, and generated the resulting audio.
That way I generated several thousand semi-random samples.
One final small thing I did to give another bit of personal character was to record myself saying “Taktile” (my artist name) and “NeuralFunk”, and then run both these samples through the VAE decoder as well as the Wavenet to get two samples based on each.
The results didn’t really resemble vocals, but they made it into the track as sound effects (for example that techy sound right at the first drop is actually one of the “Taktile” samples) .
I followed almost the exact same approach with the Wavenet.
Choosing a random number between 0 and 3, randomly selecting that number of pre-computed conditioning embeddings (or sampling a random one from a Gaussian) and combining them into a single conditioning vector, and then letting the Wavenet generate 32,000 samples (2 seconds) for each.
And again I generated several hundred random sound snippets in this way.
Interestingly the Wavenet seemed to understand the general sound characteristics of the conditioning, but not the timing information. And since it was not only trained on one-shots, but also full loops and beats, it generated some very interesting outputs.
For example, given a single one-shot percussive sound as conditioning, the result was sometimes actually a full beat comprising similar types of percussive sounds (e.g. a snare beat if conditioned on a snare).
If I keep working on this, one thing I might want to try is not to encode the entire spectrogram and use it as global conditioning, but encode individual time slices and then feed them as local conditioning to the Wavenet to get some more control over the temporal aspects of the sound.
But for now, I still had plenty of interesting samples to play with.
The one thing that seemed quite hard to generate for both networks were crashes, open hi-hats and other cymbal-like sounds. I didn’t specifically try to generate these, but in my random samples I found no convincing cymbal sounds.
But I guess, given their complex sound characteristics, cymbals have always been one of the more challenging sounds for synthesisers. Maybe this could be another interesting direction for future experiments. The Wavenet seems more promising for this since the upscaling in the VAE decoder (at least my hacky version) washes out the finer details required.
You can download all the samples here. Inside the zip file are two directories corresponding to Wavenet and VAE samples respectively.
For the VAE, filenames starting with “random” are files based on random samples from my library. Those beginning with “sampled” were directly decoded from a code sampled in latent space. For each audio file I also included a png of the output spectrogram, as well as the input spectrograms (if there were any inputs).
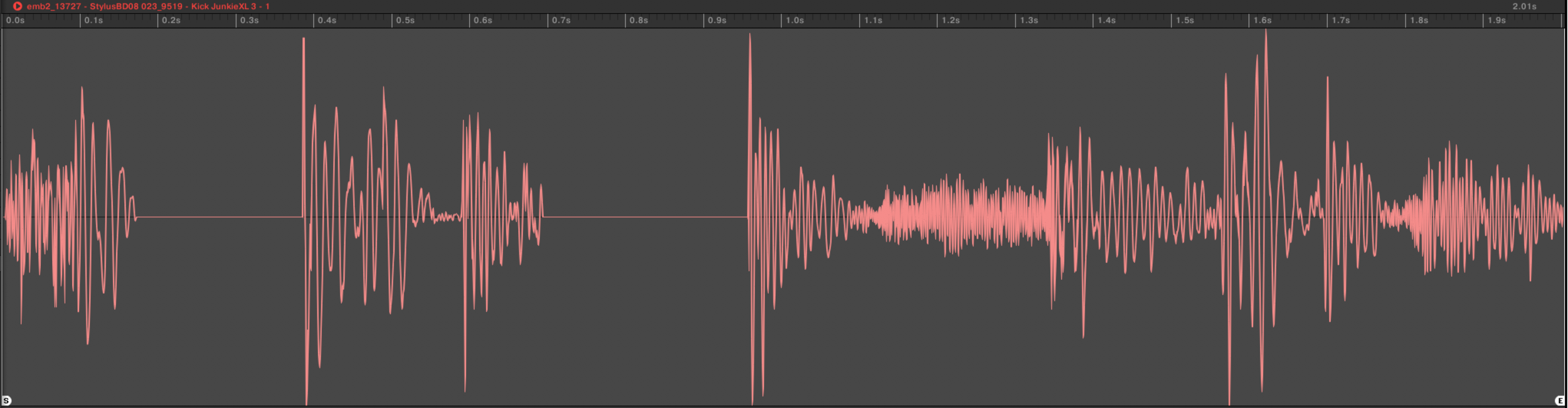
The Wavenet directory contains four subdirectories corresponding to four different models. “generated_1” and “generated_2” are unconditioned models, whereas “generated_emb2” and “generated_emb_big2” are conditioned models (the number at the end refers to the batch size I trained them with).
For the conditioned ones, the filename contains the original files it was conditioned on. E.g. “emb2_13727 — StylusBD08 023_9519 — Kick JunkieXL 3.wav” in “generated_emb_big2” was conditioned on the two files “StylusBD08 023” and “Kick JunkieXL 3” (and the other numbers refer to my own internal indexing system). This particular file is actually a great example where the combination of two simple kick sounds, both one-shots, lead to a full kick-based beat.
Feel free to use these samples in any way you want. And if you come up with something cool as a result I’d love to hear it!
The Production Phase
Having generated thousands of samples, it was finally time to get producing and turn them into something that resembled music.
I was actually also moving to a new flat during this month. While losing quite a bit of time due to that, I at least had the joy of working from a fresh and (initially) uncluttered workspace.

Although I recently started to get more into Ableton Live, I decided to do this project in Native Instrument’s Maschine since this is still the DAW I’m by far the most comfortable and familiar with. I only very occasionally switched to Live for it’s amazing warping tools.
The initial production phase was quite painful. Even though I had my VAE as a similarity search tool, it’s current incarnation has many shortcomings that made it fairly useless for this task. For example it only considers the beginning of a sample. But especially in the Wavenet case there were often interesting parts buried further inside the file.
For that reason, I actually had to manually go through all the samples and find interesting sounds. This took me two entire evenings, spending several hours each to go through all the sounds and put the interesting ones I found into groups that I roughly ordered by sound type, namely percussion, melody, drone, SFX, and bass. I then further went through the drum groups and color coded each sample by the type of drum sound, e.g. red for kick, green for snare, and so on.

Finally I copied all the kicks, snares and hats to separate groups so I could process them together later on.
In the end I had over twenty different groups, with 16 samples each, a total of more than 320 samples that I deemed interesting.
But this was by far not the end of the tedious pre-processing… As I mentioned, the interesting sound was often not at the beginning of the sample. I had to go in and isolate the part I actually wanted.

Even for simple drum sounds which seemingly started at the beginning of the sample, they often had some nasty artifacts, and I had to remove a few milliseconds.
Next came the very rough shaping. Did I want the sounds to play as one-shots (i.e. they play all the way through once triggered) or ADSR (where the sound fades out when it is no longer played)? If ADSR, I had to set the attack, decay, sustain and release parameters.
Also quite a few of the samples, especially the VAE generated ones, had some unpleasant high frequency noise so I applied some low pass filters to get rid of that.
Lastly, in order to write the track in a consistent key, in this case (mostly) F minor, I had to tune the melodic samples by pitch shifting each individually.
With all this, after many hours, the basic preparation and preprocessing was finally done and I could start making music.
The first thing I did was to lay out an Amen Break. I wanted to do this because as a drum & bass producer it just felt like the most natural thing to do when playing with new sounds. But I also wanted to re-sample it so I could chop it up and use it as a breakbeat later.
The result was quite a nice sounding Amen Break (except for the one crappy sounding cymbal in the end). For the accompanying image I thought it would be a nice touch to run the original “Amen, Brother” cover through DeepDream ;)
Click here or on the image below to listen to it. Unfortunately Instagram embedding doesn’t seem to be working so I’ll just link to it.

Next, I had taken a Monday off from work to completely focus an additional full day on this project. I got up early, all motivated, made a coffee, and set down at my desk. And then…
Nothing! Whatever I did sounded absolutely awful. I tried starting to put down some drums but didn’t get anything to sound good. Then I thought maybe start with some melodic stuff. Or bass. But no matter where I tried to start, I just couldn’t get anything decent down.
My early attempts at more sound design, adding filters, effects and modulation to the samples, also sounded terrible.
Around noon that day I felt completely demotivated and thought this project was doomed. I decided to go for a long walk.
I have previously touched on the creative power of walks. And this again proved to be the case here. When I came back about an hour later and sat down at my desk again, something magical happened. I got totally into the flow and everything seemed to come together by itself.
By late evening, not really having noticed that much time had passed at all, I had finished a lot of sound design and had gotten the general feeling of the track down. I also had most of what would later become the intro laid out.
Over the next days I did a lot of fine tuning and added additional elements to the intro. But whenever I tried to move beyond that I felt stuck again.
Luckily, my buddy D.A.V.E. had immediately offered to collaborate on this when I told him about the project.
D.A.V.E. is not only an amazing DJ and producer, he’s also a great teacher, and he helped me a lot with this track. I highly recommended checking out his stuff, he’s got some really cool tutorials and other things coming up in the near future (and there might even be some more collaborations between the two of us).
So at this point, having developed the general idea and feeling of the track but otherwise being stuck, I handed it over to D.A.V.E. He immediately got into it and sent me some of his thoughts and ideas the next day.
Before he got involved, I was particularly struggling with the drop that would follow the intro. He suggested to try doing it in half-time, almost giving it a feeling of Trap, and laid down some beats on which I later built.
He also came up with some synth part which, to be totally honest, at first listen I actually thought was kind of annoying, but then totally grew on me and with some modifications turned into one of my favorite elements.
That’s one really cool thing about collaborating. Even if you don’t always exactly like or agree with what your collaborator made, it’ll give you new ideas and helps you get unstuck. You can modify it and make it your own, and in the end come up with something cool that you would’ve never dreamed up by yourself.
Over the next couple of days we went back and forth with updates on the project. The fact that we were in completely different time zones (D.A.V.E. in London, I in Tokyo) was actually really helpful to coordinate stuff. In the evening (my time) after work we’d have a quick call to align and talk about ideas, then I’d work on the track for a couple of hours. At the end of the night I’d send him my latest version, and by the time I got up the next morning he had sent me some new ideas back.
Eventually over the course of about a week, NeuralFunk grew into what it is now. It’s not at all the kind of Neurofunk track I had envisioned when starting this project, but it was always meant to be on the experimental side anyway.
Below is the (almost) final arrangement in Maschine. It’s definitely the Maschine project with the most different groups and patterns I’ve ever made. And my terrible (or rather almost non-existing) naming scheme also didn’t help navigate this project as it grew (sorry D.A.V.E.).

There were many things I would have liked to change or improve, particularly the bass and other low frequency elements are quite a mess, but there was simply no time left.
So finally I just decided to call it done and have some fun with it, jamming over it. To see a video of me improvising some live stuff click here or on the image below.

Overall, I think the project turned out quite interesting. To be honest, the only part I’m completely happy with is the intro, and given more time I would probably scrap a lot of stuff and redo it, but considering the time constraints and also the experimental nature of the samples themselves, I think the result is not too bad.
As a side note, the same thing actually goes for this article. I wanted to get it down as quick as possible and essentially publish along with the track before the NIPS workshop deadline, so it didn’t go through quite as much editing and reach the same kind of quality that I usually aim for with my writing. Sorry for that! If you made it till here anyway, thanks for putting up with my drawn out rambling!
There are definitely many directions in which I could take this from here. Some of them I’ve already mentioned above, and many more come to mind.
For example I would like to improve the encoder/decoder architecture in the VAE from a simple (de)convolutional network that treats the spectrogram as it would any other image, to something that takes the different information along the two axes into account.
I’m also still thinking of going back to my original idea and integrating the similarity search (and maybe even the sample generation) into some interesting tools for live performances.
But first, I need a break and catch up on some sleep!
By the way, if you’re interested in more of my music, also check out my last track, which was produced in a more traditional way! ;)